The effects of data fragmentation in a mixed load database
(c) 2007, Dmitry Dvoinikov dmitry@targeted.orgAbstract
This article discusses the effects of data fragmentation when the database is under mixed load. In an experiment that follows, a specific workload is executed twice against two different databases to support the theoretical discussion and yield some numbers. The tested database engine is PostgreSQL, although the results should remain true for most relational database engines.Introduction
A simple operational database is often created without any thought of architecture or any prior planning. It may contain a single large table holding most of the current data. This main table accumulates incoming facts and is supposed to be going like that forever. As time passes, some data piles up and suddenly it appears an easy solution to start running reports off the table. After all it is the table, right? And so, it keeps accepting a steady incoming stream of facts, but now it also serves a gradually increasing flow of more and more complex analytical queries. Besides, no maintenance is performed on the database, other than backing it up perhaps. A few months down the road the analytical queries suddenly start exhibiting awful performance and a typical thing to blame is what, a lowly hardware, an incapable database engine or the inherent complexity of analytical queries. Then a more fashionable database is installed on a more powerful server and the story starts over.To quickly dismiss the declared problems, today's entry-level server (even like the one I will be using in the following experiment) would eat yesterday's flagship for breakfast. The database engines have matured over the years and have often converged in their basic principles and feature sets. The problem with complex queries may exist but should be solvable as soon as developers and administrators work together.
I'm not at all advocating the approach to run reports off a main operational table, mixing different data access patterns like that is wrong. But the fact is – some database applications do require such mixed load and I will just use one simple case as a demonstration of the disastrous effects that data fragmentation has on a database. To do so, I will run identical workload two times – first (which I will call "fragmented") through a database with no maintenance whatsoever and the other ("defragmented") through a database with minimal online defragmentation. This particular experiment I will run on PostgreSQL although much of the following discussion holds true for most other databases.
Theoretical background
Here is how the main operational table looks like: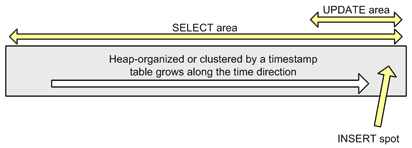
It is typical to have records inserted at the logical end of the table and only relatively fresh records updated or referenced on individual basis. As soon as a record ages, it no longer sees any updates and is seldom selected alone, but is frequently selected in a bunch with a lot of other records. For the sake of this discussion I will assume that the table accumulates financial transactions - payment records from different customers. What is important is that each record in the table is tagged with the customer id, there are many customers and the payments arrive in random order. Here is how the table looks like then:

The simplest report (account statement) will then fetch all the rows for a single given customer and perhaps sort or apply aggregates. What's wrong with the above picture with respect to such request is that customer's rows are scattered across the entire table, so that to fetch every single record, the database engine has to read an entire page from the disk, and that is not only a separate physical I/O operation, but worse, if the required rows are sparse (and they are) it requires a disk head seek. Besides, each read from the disk will likely bring in a single worthy record. This means that we have about as many logical reads as we have records in the result:

It would be great if all the records for the same customer appeared together, in physical proximity. This way a fast sequential read will bring into memory just the records required and nothing else. The following scheme demonstrates the ideal situation (this is what Oracle's sorted hash cluster does theoretically):

In practice it would never be that clean and beautiful unless you actually take time to physically reorganize the table every now and then. The reorganization process may take names of defragmenting, rebuilding indexes, dumping and reloading the table or clustering:

The problem is, however, as the table grows, it takes more and more time to reorganize it like that, and the table may have to be taken offline for the duration of entire process. There may be other problems. In PostgreSQL specifically, clustering is something like
INSERT INTO t SELECT * FROM t ORDER BY cid;wrapped up in a non-standard operator
CLUSTER t__idx__cid ON t;and although it can be performed online on a live table, it is notoriously slower than just the mentioned SQL query.
Granted, the database engine may attempt to keep the table clustered all the time (just like the mentioned sorted hash would) and partitioning may help, but I'm going to demonstrate the effects of simple online defragmentation, which should support my point that even a little bit of contiguity may have wonderful effect on performance. What I'm going to do in the second workload run is to replace the original table with the view concatenating two tables – one current operational containing only records being actively updated (in real life – records less than one day old), and another archived containing records which are highly unlikely to ever get updated, mostly participating in analytical queries:

As soon as the t_current table fills up so that its tail contains just enough unchangeable records to bother processing, the tail is cut off and appended to the t_archive table sorted by customer id. This way t_current will always contain at most two days worth of records and t_archive will grow unconstrained but will have the customers' records somewhat clustered. Therefore, a query fetching all records for a customer will need to scan through much fewer islands of densely packed records.
The view created to replace the original table:
CREATE VIEW t AS SELECT * FROM t_archive UNION ALL SELECT * FROM t_currentwill behave almost exactly as the original table, as soon as we equip it with a few rules.
Rule system is a PostgreSQL-specific feature which essentially allows intercepting queries at execution time and making them do something else. In this case we need a single insert rule so that inserts to t actually go to t_current and two update rules so that each update on t will in fact run two identical updates on t_archive and t_current. Without further discussing this, we may just assume that t is an updateable view which behaves very much like the original table.
But the table layout and physical I/O are not the only sources of trouble with data fragmentation. Another database component which is heavily affected is the shared buffer pool.
The buffer pool is a dedicated memory area, shared between all the database engine instances (hence the name), and it basically contains the data being currently accessed. The buffer pool is limited and often fixed in size therefore it can only hold only so many data pages at a time. As soon as the database engine needs to reference another data page and the shared buffer pool has no free space, some of the currently resident pages need to be evicted.
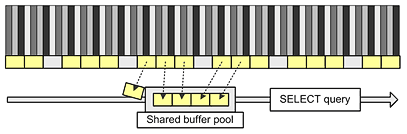
Note that it's only for the diagram that the buffer pool is being used in the FIFO fashion, a real database engine may replace the pages in the pool in any order.
The so-called common wisdom recommends not to configure the shared buffer pool in PostgreSQL to be very large, because, they say, when operating system implements effective file caching, large portions of system memory automatically become sort of a level 2 shared buffer pool – if a recently evicted page is needed again in a short while, while it still resides in the filesystem cache, no physical I/O is necessary, it's simply copied back from kernel memory.
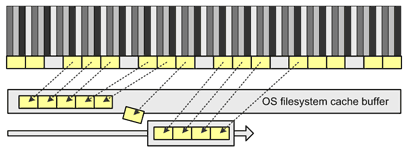
This appears to be a valid advice but it is still worth a closer look. One case where this "buffer pool extension" principle does not work is when the page to be evicted is dirty (has been changed in memory since it has been read from the disk). A dirty page cannot be evicted without previously being physically flushed to the disk. It cannot be simply discarded like a clean page, because doing so would result in a data file inconsistency and require recovery from the transaction log.

Therefore, in presence of concurrent updates and inserts, select queries will result in a constant stream of random I/O writes to the underlying data files. Technically, such write may not result in an immediate synchronous physical I/O operation (as is the case with transaction log), but the OS filesystem cache will only keep the page to be written only for so long as to optimize the disk access pattern, meaning – almost no time.
This implies that in spite of any OS caching, your database cannot have more dirty pages than a shared buffer pool can hold. To be fair, this is always true, and you wouldn't normally have that many dirty pages – checkpoints and writer processes will see to that. Besides, having a lot of dirty pages is bad in case of a failure when all the dirty pages are lost and need to be recovered from the transaction log, which may take a lot of time.
Another case where the filesystem cache usefulness is reduced is the following. As the number of concurrent queries increases and they start to compete for the space in the shared buffer pool, the pool becomes a major source of contention as each query demands more pages for itself.
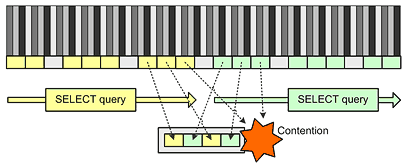
Theoretically, a simplest query of
SELECT * FROM twould have flooded the buffer pool with pages not to be accessed again any time soon. Moreover, should the amount of selected data have exceeded the buffer pool size, the entire buffer pool would have been entirely wiped out with pages being immediately evicted and impossible to reuse without being re-reading again. Such scenario is extreme but the database engine needs to specifically protect itself from such buffer pool trashing. The buffer pool management algorithms are probably among the most valuable database vendor know-how's. PostgreSQL specifically uses an advanced algorithm trying to separate expendable short-living pages from the precious long-living ones.
Now, notice that no matter if the shared buffer pool is backed up by a filesystem cache or not, the queries will still compete for space in the buffer pool. Doesn't matter if a page has been found in kernel memory and not been read from the disk - it has to be copied to the buffer pool before the database can access it.

Having filesystem cache support will save us a physical read sometimes, but it will not rid of contention at the shared buffer pool.
Armed with all this knowledge, let's look again at what happens when a highly defragmented data is accessed, this time with the shared buffer pool included to the diagram.

The key thing to note is that both the data file and the buffer pool have page granularity. Even if all you want is a single record, you have to read the whole page from the disk. Likewise, no matter if you need to process a single record from the page you have just read, you have to allocate an entire page from the shared buffer pool just for it, possibly evicting other pages.
This leads us to the pinnacle point of this article -
Data fragmentation is not only bad because it results in lots of physical I/O but also because it reduces the effective size of the shared buffer pool from N pages to N records, thus by a factor of a 100.
For example for a PostgreSQL shared buffer pool of 256M and a default page size of 8K, the shared buffer pool can contain at most 32K pages of data. But with heavily fragmented data it becomes just 32K records. Think about it – no matter how fast hard drives you have, no matter how much physical memory, a database cannot reference more than 32K records at a time without having to swap pages around, likely causing physical I/O.
Finally, let's proceed to the experiment.
Experiment workload
The workload simulates the described scenario where the database processes a stream of both OLTP requests accessing single record each and simple analytical requests accessing a bunch of records each. The records are never deleted, therefore the test database grows indefinitely. The goal of this experiment is to demonstrate the effects of fragmentation as the database keeps growing.Technically, ten client sessions are connected to the database and repeatedly execute the same stored procedure in an infinite loop at full speed. Each stored procedure run is performed in a separate explicit transaction. The stored procedure being executed is the same, but upon each run it chooses an action to perform at random as follows:
-
25% chance of "insert"
Insert single record with sequential record id and random customer id. This corresponds to initial payment creation.
-
25% chance of "update"
Update a single record by random record id inserted within last hour. This corresponds to payment status change or something like that.
-
25% chance of "select one" (record)
Select a single record by random record id inserted within last hour. This corresponds to the payment browse.
-
15% chance of "select hour" (worth of records)
Select all records for a random customer for the last hour, sorted by insertion time. This corresponds to a daily account statement.
-
10% chance of "select all" (records)
Select all records for a random customer, sorted by insertion time. This corresponds to a yearly account statement.
CREATE TABLE t ( ts timestamp NOT NULL, -- date and time of insertion id int NOT NULL, -- record id generated with a sequence cid int NOT NULL, -- random customer id pad varchar(200) NOT NULL -- "the rest" of the record fields );where ts is the current time at the moment of insertion, id is the sequence-generated unique number, cid is a random customer id in range 0-9999, and pad is a stuffing to replace the rest of the unspecified fields. As pad has a random length, 100 bytes on average, the typical record size is around 150 bytes (ts + id + cid + 100 + PostgreSQL mandated 27 bytes per record). The tables have two indexes to them - one by (id) and another by (cid, ts).
A typical record can therefore have the following lifecycle:
1. Get inserted:
INSERT INTO t VALUES (now(), 123456, 1234, '*' * 130)2. Get updated (possibly more than once):
UPDATE t SET pad = ‘*' * 180 WHERE id = 1234563. Get selected on an individual basis (possibly more than once):
SELECT * FROM t WHERE id = 123456Note: only records inserted within the last hour can be selected or updated individually.
4. Get selected along with all the customer's records for the last hour (possibly more than once):
SELECT * FROM t WHERE cid = 1234 AND ts > now() – 1 hour ORDER BY ts5. Get selected along with all of the customer's records (possibly more than once):
SELECT * FROM t WHERE cid = 1234 ORDER BY tsThere is no doubt that the performance of a database under described workload will degrade as the size of the table increases, the question is – how bad and how fast would it degrade.
Online defragmentation
As mentioned earlier, the second database will be equipped with a simple online defragmentation facility – a separate stored procedure executed periodically. The defragmentation process is executed in a separate explicit transaction and cannot violate data integrity. Now the question is – how frequently defragmentation should be performed ? If you run it frequently, each defragmentation run will take less time and affect the main workload less, but the archive table will be more fragmented. If you perform it infrequently, the archive table will be better clustered but the defragmentation process will take more time and memory and affect the main workload more. I came to the following decision – each defragmentation run should deliver to the archive table just enough records so that each customer's rows occupy exactly one page. This seems to be the minimal reasonable clustering.The calculations are as follows then: for a page size of 8K and average row size of 150 bytes, each page accommodates about 55 rows. Since there are 10,000 customers and we need a separate page worth of records for each customer, it gives 550,000 records to be sorted and transferred to the archive table on each defragmentation run. To put it simply, the defragmentation procedure is run whenever another 550,000 records are inserted to the current table. That many records occupy about 80Mb and should comfortably be sorted in memory, provided the session is configured appropriately.
Hardware testbed
HP DL 320 G51 x 2.4GHz dual core Xeon CPU
2Gb RAM
2 x 80Gb 7200RPM SATA HDD striped in a software RAID-0
Software configuration
OS: FreeBSD 6.2 SMPDatabase: PostgreSQL 8.2.4, configured with
- 256Mb shared buffers
- 1Gb effective cache size
- automatic vacuum and analyze
- 15 minutes checkpoints
- aggressive background writer
Readings collected
The following parameters were being measured and collected in the course of the benchmark:- Average request duration in milliseconds, collected separately for each of the five request types – "insert", "update", "select one", "select hour" and "select all".
- Amount of physical I/O generated separately by reads and writes.
- Percentage of dirty buffers in the buffer pool.
Experiment results
The workload has been run for a week against each of the two databases independently. The "fragmented" database performed worse, as expected, and only managed to process 11 million rows. The "defragmented" database performed much better and has been able to process about 17 million rows. The results are shown on the following diagrams. The X scale of the diagrams measures the number of rows in the table, not time elapsed, therefore the "fragmented" diagrams appear significantly more narrow. Nevertheless, all the diagrams correspond to the same running time.Average request duration in milliseconds (click to enlarge):

Amount of physical I/O, percentage of dirty buffers (click to enlarge):

Results discussion
Predictably enough, there appear to be three clearly different regions, marked A, B and C on the graphs.Region A: the entire database is smaller than the buffer pool, all the data is always unconditionally available to the engine.
Although it appears to be a trivial case because all the requests are so fast that they are not even detectable on the graph, the I/O diagrams tell an interesting story. As the records are inserted at the amazing speed, the buffer pool usage skyrockets, and because of the simultaneous hail of updates, the percentage of dirty pages follows closely. Nearly all buffer pool pages become dirty at this moment.
There is an overwhelming amount of physical I/O writes during this entire period. It cannot be justified by writes to the transaction log alone, and is probably due to the dirty pages eviction resulting from combined effects of buffer pool manager attempts to reuse the pages, background writer process and checkpoints. I/O reads, there are none.
Region B: the database size grows above the buffer pool but is still smaller than the physical memory available on the server.
This is an interesting period of time. The database is under load but it appears to be in stasis – all the requests execute at about the same speed, the amount of I/O writes has dropped significantly, but is still high and at about the same level. There is still no I/O reads – the database is completely backed up by the filesystem cache.
Note however, that the "select all" requests timing grows linearly. This could have been rather unexpected result, after all, why would an all-in-memory request take more time ? But it perfectly illustrates the discussed point of buffer pool contention – it is not enough for a record to present in physical memory to be accessed – the page it belongs to has to be brought to the buffer pool.
Another, rather curious result is that it takes more time to insert and update a physical table than a view, just note how the insert/update lines are higher on the fragmented table graph. This is probably because the inserts and updates to the view t are always redirected to the table t_current, which is always smaller in size (and has smaller indexes too).
Also note that in the defragmented run, select queries wipe out fewer pages than they do in fragmented case. This results in fewer forced evictions and significantly higher percentage of dirty pages. This may not be very important at the moment but it will be in region C.
Region C: the database size becomes larger than the amount of physical memory on the server.
As the physical memory boundary is crossed, the fragmentation deficiencies are immediately surfaced. The fragmented database starts trashing almost instantaneously. Not just that, the average time for a single "select all" query in the fragmented database grows exponentially, so high in fact that it cannot be conveniently drawn on the graph and is represented by a fictional dotted line. At 11 million records, the time to execute a "select all" reaches 11 seconds. At the same database size, the unfragmented database runs it in less than 500ms !
As the amount of physical reads starts growing, the writes take a steep fall because the hard drives now have to seek a lot. With the fragmented database the fall is ugly and edgy and makes the impression of hitting the wall. With the defragmented database the fall is smooth and nice and makes an impression of being able to keep going for a while.
As mentioned previously, the defragmented database can afford to keep more dirty pages in memory, which allows squeezing in more concurrent reads without having to evict every page. The defragmented database thus demonstrates better I/O rates.
Finally, at its 17 million records, the behavior of the unfragmented database doesn't indicate that it is preparing for anything unusual. The request times keep growing smoothly and linearly, the amount of I/O reads keeps rising asymptotically and the amount of I/O writes keeps falling for the hard drives of limited capacity to accommodate more and more reads. It seems like it would easily go like that for another 10 million records. The fragmented database would have been long since dead by that time.
Conclusions
- Fragmentation is evil. A fragmented database could not be larger than the physical memory installed on the server. Anyhow, this is true in presence of analytical requests spanning significant portions of the database. Purely OLTP load will have no performance penalty in a fragmented database.
- Besides being bad for the I/O performance, fragmentation does affect buffer pool management and the effects are clearly visible. This is very true for PostgreSQL which has very specific buffer pool management policy, and is likely to be true for other databases as well. How exactly any other database's buffer pool manager behaves under fragmented load cannot be seen from the executed experiment.
- The limiting factor is physical I/O (as usual), and head seeks kill it more efficiently than anything. For a logical striped drive capable of linearly streaming 80Mb/sec, under heavy seeking the effective throughput drops to about 5Mb/sec.
- The database needs not to be perfectly defragmented. Even having related records to occupy the same page improves performance greatly.